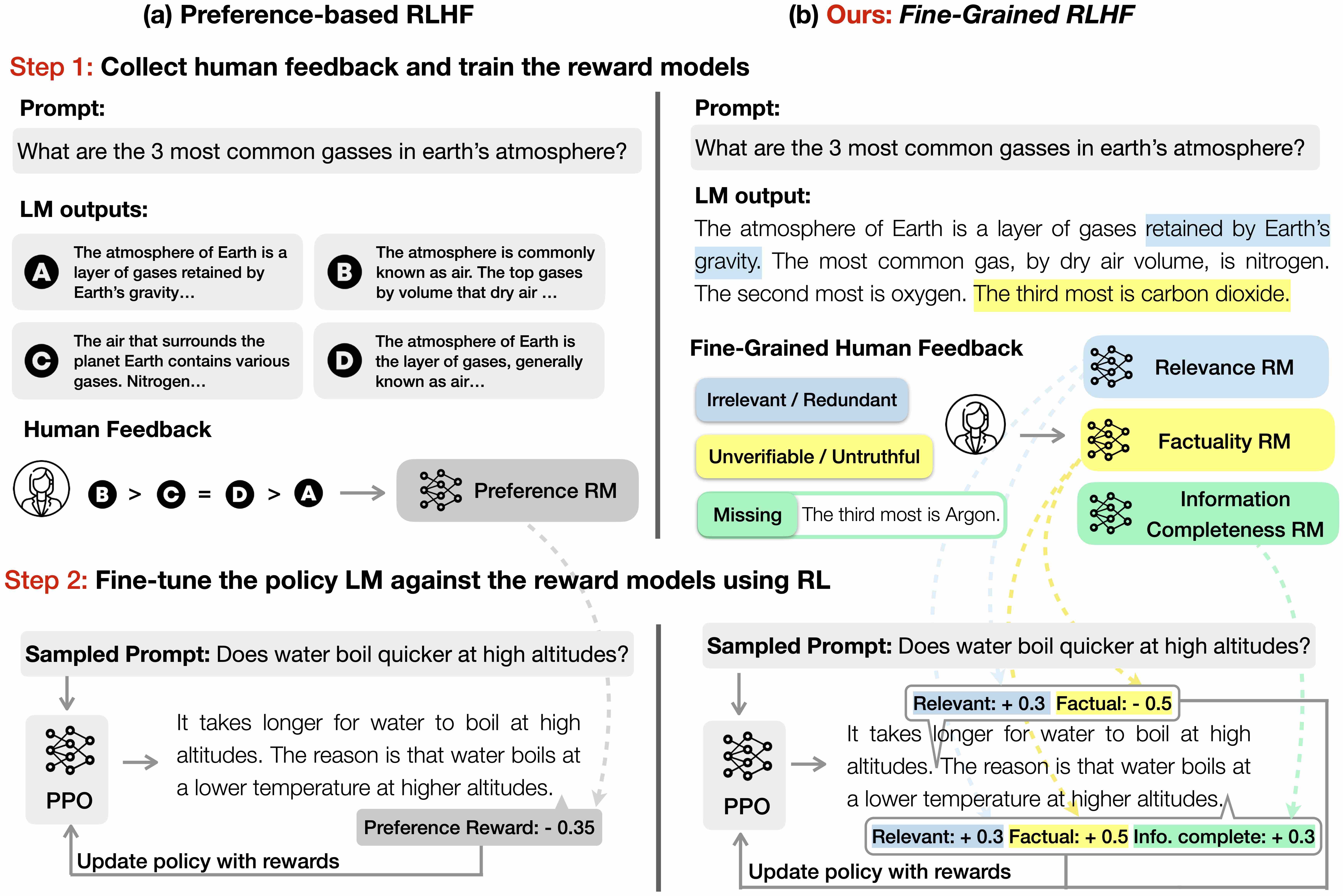
We collect QA-Feeback, a dataset of long-form question answering, with human preferences and fine-grained feedback.
QA-Feedback is based on ASQA, a dataset that focuses on answering ambiguous factoid questions.
There are three types of fine-grained human feedback, and we train a fine-grained reward model for each of them:
C1: irrelevance, repetition, and incoherence (rel.); The reward model has the density level of sub-sentences; i.e., returns a score for each sub-sentence.
If the sub-sentence is irrelevant, repetitive, or incoherent, the reward is -1; otherwise, the reward is +1.
C2: incorrect or unverifiable facts (fact.); The reward model has the density level of sentences; i.e., returns a score for each sentence.
If the sentence has any factual error, the reward is -1; otherwise, the reward is +1.
C3: incomplete information (comp.); The reward model checks if the response is complete and covers all the information in the reference passages that are related to the question.
This reward model gives one reward for the whole response.